


What does it take to build an automated call centre analytics solution that is capable of capturing mass structured data from interactions with clients and performing analytics to readily derive value?
“At Synthesis, we aim to prove that it is not only (finally) possible to be compliant with regulatory requirements at a reasonable cost but also to start making data-driven decisions in areas including, but not limited to, quality assurance, customer retention, marketing, client experience, and resource allocation,” says Hugo Loubser, Associate Principal Machine Learning Engineer at Synthesis.
The call centre analytics solution may be utilised for any use case that requires understanding the interactions clients are having with your organisation. The infrastructure is designed to be general in its feature extraction, with minimal changes needed to retrofit to any new use case by simply requiring one component to be tailored to incorporate the business logic that formulates the use case.
Quality Assurance Challenges
Regulators require at least 5% of calls to go through Quality Assurance (QA).
Failing to comply with these requirements could have multiple repercussions, some of which include:
- Penalties and fines if calls are found to be non-compliant with AML/FAIS/TCF/NCA/POPI, etc.
- External fraud if customer authentication is not performed correctly.
- Reduced customer service levels if staff do not act professionally resulting in lost revenue.
- Legal Risk associated if a client is not made aware of the necessary terms and conditions of a product.
A typical bank could make and receive approximately 10 million calls per annum.
“With the regulatory requirement set at 5% of call volumes, this means that with 1370 calls per day, a typical sales call with a duration of 30 minutes, QA teams would have to listen to 683 hours of calls for just one day’s worth of interactions. In other words, it would take 85 days for one person to listen to just one day’s worth of calls. No company has the resources or the budget to be able to listen to calls at this scale,” explains Hugo.
What is the Solution?
Building a custom, automated architected solution effectively acts as a feature engineering pipeline that is able to capture semantic information in the interactions being had between call centre agents and customers. This is possible due to recent breakthroughs in automatic speech recognition (ASR) and natural language understanding (NLU) technology as well as the direction in which the natural language processing (NLP) research community has been heading.
“Not only will this solution allow an organisation to be compliant, but it allows efficient scaling that could lead to processing 100% of call volumes for a significantly lower cost than the manual alternative,” says Hugo.
Understanding the Solution Architecture
By utilising Amazon Connect and Salesforce, metadata is captured as interactions (calls) occur.
“From Connect, we receive the actual recording and information on the call itself. Some of this information includes which banker was speaking to the client, from which number the call was made and received, the duration of the call, in which queue the client may have had to wait, and which recorded messages did the client listen to.
From Salesforce, we receive information on the type of interaction such as which product was discussed, what kind of service was provided, whether there were previous interactions relating to this sale/service request, and more. This data is aggregated in either S3 (a unique directory structure for each live stream that is recorded) or in relational databases (metadata)”, explains Hugo.
Given that this is a completely automated solution, the entire pipeline is set off by a scheduled trigger using Amazon EventBridge, typically, at the end of the day to allow all business for that day to be concluded, and Lambda functions that orchestrate the integration between different components. The scheduled run starts off by loading and linking the recordings and metadata from the Connect and Salesforce ecosystems. Connect’s metadata resides in a Redshift Data Warehouse and Salesforce has a proprietary data structure built into it that can be queried using their Salesforce Object Query Language (SOQL). These artifacts are then transferred to the raw data repository in S3 where it’s being viewed by S3 triggers that set of the succeeding components. Once new content is detected in the recordings repository, a Simple Queue Service (SQS) is created to push transcription jobs to Amazon Transcribe for the audio to be converted to text.
Amazon Transcribe is also capable of Speaker Diarization, allowing us to separate the client’s verbiage from the agent’s verbiage. Once the transcription is completed and stored in the processed data repository, the text is pushed to the inference pipeline for the language model to process what was said. The inference pipeline contains three components, defined as SageMaker processing jobs to allow longer runtimes and custom Virtual Machines (VM) since a more powerful machine is needed to load and use the Transformer Language Model. These three components include pre-processing, inference and post-processing.
“At this stage, we should mention that the inference pipeline is the only component that needs to be changed for this solution architecture to be used for any other use case” mentions Hugo.
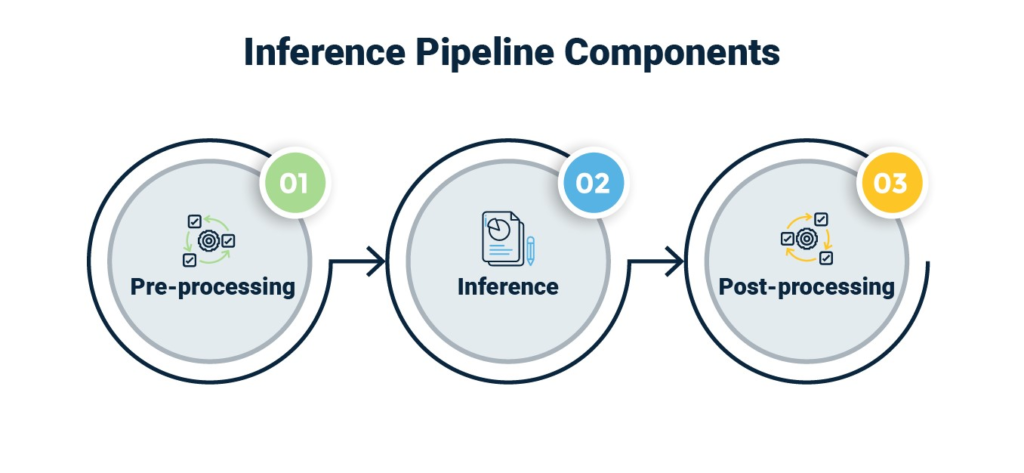
- The pre-processing prepares the text data along with any additional metadata and puts it into a format that the model expects. Any additional data cleaning and Personal Identifiable Information (PII) redaction components are implemented in the pre-processing step. Once the data has been prepared, it is sent through the inference component.
- The secret ingredient that makes this entire solution possible and so incredibly effective is the type of AI that is used in the inference component. We make use of a pre-trained Transformer model that allows us to obtain a language-agnostic numeric representation of the verbiage that retains semantic and syntactic information in a way that allows us to perform meaningful analytics on it. These numeric representations are called embeddings.
- Once we have the embeddings, we invoke the post-processing component. Here we apply business logic to use the model output to derive value from it.
“In the case of QA, this business logic includes having a list of the phrases that the agents are expected to utter to clients. We then use the embeddings to determine whether or not each of these phrases was spoken. This means that if we have a list of 50 phrases that need to be spoken for that call to be deemed compliant, we obtain 50 output scores for each of the incoming phrases from the conversation. These outputs act as probabilities that the specific compliance phrase was found in the spoken language” advises Hugo.
Going beyond Quality Assurance
Call data is annotated with valuable insights. It allows for access to data that could answer questions such as:
- How much of my workforce is being utilised?
- Which products are being discussed most often?
- How efficiently are the agents picking up calls and how much silence is picked up during calls?
- Are calls taking longer for certain agents/products? Maybe the scripts/training material needs to be updated.
- At which times of the day/week does the call centre experience the largest/smallest call volumes?
In order to understand why clients are calling the call centre, we simply need to swap out the type of model used in the inference component of the architecture. This could be implemented as either a supervised or unsupervised approach. We could either try to extract topics in a data-driven way, or we could map them to a pre-defined list of intents. Typically, for this type of use case, we would suggest implementing an unsupervised paradigm first to understand your data better (as an exploratory data analysis (EDA) exercise) and then switch to a supervised paradigm to refine and deepen the way in which the model tries to understand the verbiage. This will allow you to answer questions such as:
- Why are my clients calling?
- When are my clients calling to discuss which topics/products?
- Why are calls being dropped prematurely? (Leading to missed opportunities, cross-selling, etc.)
“We can say that for a specific call, that included Employee A and Customer B, we know that Product A was discussed, whether or not the Employee was compliant (and why they were not compliant in the negative case), what the customer’s sentiment was (towards the organisation, product or agent) and what if any, complaints or compliments were made.
As mentioned, this solution architecture can be utilised in many ways other than QA. If you can formulate the business rule, you can probably use this architecture to derive the data from the interactions with your clients,” concludes Hugo.
Author: Hugo Loubser, Associate Principal Machine Learning Engineer at Synthesis.

Ends
For more information on the innovative work Synthesis has done for its clients, contact us on 087 654 3300
About Synthesis
Synthesis uses innovative technology solutions to provide businesses with a competitive edge today. Synthesis focuses on banking and financial institutions, retail, healthcare and telecommunications sectors in South Africa and other emerging markets.
In 2017 Capital Appreciation Limited, a JSE-listed Fintech company, acquired 100 percent of Synthesis. Following the acquisition, Synthesis remains an independent operating entity within the Capital Appreciation Group providing Cloud, Digital, Payments and RegTech services as well as corporate learning solutions through the Synthesis Academy.
